KESA - Event Sourcing
Why Kubernetes On-Prem and a Glimpse into Our Setup
KEDAS: SYNC RELATIONAL AND NON-RELATIONAL DATABASES USING KAFKA
A CNN Approach for Recognizing Traffic Signs
Selecting between PoCs, Prototypes, and MVPs.
Many companies struggle to choose the aptest technique to validate their concept and choose between POC, Prototypes, and MVP. In our previous context, we discussed the definitions, applications, advantages, and use cases of these elements. You can find the link to the article here and peruse the write-up for a comprehensive understanding.
It is essential to know that it depends on the business idea or the end product and your target audience (B2B, or B2C, B2B2C); and you may need to use PoC, Prototype, MVP or a combination accordingly.
Idea validation using these concepts will ensure that your final product will enable you to achieve its ultimate goal.
A PoC can usually provide a direct response to whether the concept will be viable or not for the target audience. Idea feasibility will be measured here, and with the comeback, you can decide whether to proceed with the existing plan or not. Furthermore, a PoC can help convince your initial pre-seed investors that your concept can be implemented and is technically viable.
On the other hand, MVP enables companies to grasp information about the target user's experience and respond to the core business purpose of the application. The insights received from actual users helps to validate the overall objectives, identify the user pain points, and address the issues over time.
If you want to present how exactly your final product will look like, or manifest the main design elements, prototyping is the best way to give the big picture to the end user. It further helps to run multiple test areas while saving your resources. If you are looking for investors to work on your project, a tested prototype is the best way to demonstrate and pitch your product.
Should PoC, Prototype, and MVP be Throwaway Builds (Minimum Initial Investment)
It is always better to look at PoC and MVP as throwaway codes. If your business idea takes momentum and finds traction, it is vital to build everything from scratch with architecture and design to cope with it for the next 3 to 5 years.
For PoC, think of the least expensive way to implement. Typically, when developing a PoC, factors like product scale, architecture, UI elements are not considered. Instead, the requirement is to check on technical feasibility and customer feedback on your new product idea or a particular feature.
With all things considered, your PoC will be a hardly scalable piece to turn out for something decent. Hence, it is better to consider it as a throwaway build.
In relation to prototyping, it can be either a throwaway or a part of your final user interface, depending on the model type you select. For example, you can use rapid throwaway prototypes to receive user feedback and discard it later. These models are used to validate the system functionalities and requirements. Hence, it needs to be removed as it does not add any advantage to the final UX/UI elements.
For MVP, you may have to build in a way that could cope up with the demand for the next 12 to 18 months (Not a rule of thumb, but empirically proven ). It is common to see startups control the growth without hurting long term plans to build the post MVP version. However, for the long run, it is essential to opt for a complete rewrite ensuring your final product can have flexibility, extensibility and adaptation with upcoming technology and supplementary changes.
A Guide to Choose from Poc, Prototype, and MVP
Exhibiting a decision matrix using a table. - includes questions and scores for users to choose the correct method for their products.
Check out the reference tables at the end of this article.
Decision Matrix
| Parameters | POC | Prototype | MVP |
| Use Case | For Technology/Market/Behavior disruption (completely new idea, so need to prove a concept is viable to build) | To verify user journeys and messaging in a solution are understood by the intended users. Save time and money. Could used to attract seed funding | Get actual users to use your solution to solve the identified problem. Evaluating your solution solves the problem in an acceptable manner. Gather feedback from users to improve upcoming versions of the solution. Aim to the initial target audience response |
| Purpose | To verify technical/market/behavioral assumptions before getting down to development. / To clarify which way to go with the development. Convince internal stakeholders | Make the application usable for its intended users. To assure that the end users could navigate and get the job done using the solution. It is the working model of several aspects of your product. Prototypes help make decisions about product development and reduce the no. of mistakes and waste. | To prove, your solution is effectively solving a problem and it is effective enough for the customer to pay for solution.To get the minimum version of the product to the market |
| Form of implementation | Most rudimentary implementation to prove the relevant disruption is viable to implement | High or Low fidelity Wireframes/UI, users could navigate through different screens but nothing has been implemented | Usable solution by its real user, just to solve the identified problem (nothing more, nothing less) |
| Target audience | Internal users (Decision makers about the project GO/NO GO) | Specifically selected sample of target audience (real users). Should be able to access more than once to verify the prototypes (should be able to involve with iterative process of prototype building) | Sample of target audience. Easily accessible, Give genuine feedback. Test the product with a pre-selected potential customer group |
| Cost | Less budget and is ideal to collect internal funding. Might have to invest on new tools and accessories. | Much less cost to build the prototype compared to PoC or MVP. More time/resources spent here saves time/resource at the expensive development phase | No compromise on quality as the end product would be used by real users. Cut the cost by reducing features, not the quality. Well-defined budgets and looks for investment |
| Human Resources | Requires technical experts to develop the basic concept. Could involve tech related R&D | Less technical resources as no coding / development is involved. Need to recruit testers, Iterative design processes | Here you are developing the actual product (at a smaller scale with less features) So needs full technical expertise |
| Risk Evaluation | PoC involves the highest risk or all. But lessen the risk in upcoming phases. | Reduce the risk in terms of user satisfaction in product navigation | Reduce the risk of losing time and resources of the full scale development |
| User Interaction | N/A since is its used internally | Gives an overview to the end user how the end product will look like with basic elements and navigation. Highly interactive with users but without real functionality. | Full user interaction. UI/UX, Key Functions and even feedback from users also a part of interaction |
| Apparent time to create | If you have several options or if you uncertain about the feasibility of the concept | When you are confident about your idea and needs to start and test the design process | When you are positive about the idea and the design, and ready to launch it to the market |
| When to Show the investors | Pre-seed / Seed | Pre-seed / Seed | Pre-seed, Seed, rarely for Round A |
| Cashflow | Negative (expenses only) | Could leads to Positive cash flows from Investors (Seed level) | Should lead to Positive cash flows from service revenues & Investors |
| Extended use | Can be used to develop MVP | Output can be used to develop the solution. No waste. If the prototype consist of UI design, it could be used for the development | Can be expanded and used for the full version of the product. You may have to throw away the code (Do not hesitate to do so) |
| What you should not do? | Invest time/resources to make the PoC usable to others.Implement things that have been already proven | Use placeholder content or graphics. Train/Assist testers. Test how UI/UX work on real environment | Compromise on quality Implement extra/supplementary features |
| Outsource or in-house work | At this stage, you are working on an idea to check out its possibilities of turning it into reality. Hence, it is ideal to do in-house to ensure that your concept would not be revealed to third parties /competitors. | Prototypes can be fully outsourced as they will be exposed to the public for test-run purposes. | MVP can be done internally or with the contribution of a third party. A mixed team is preferred here to build up the product. Here, the expertise (outsource party) can help with the best techniques while the in-house team is conscious of the progress/development plan. |
Final Take Away
Building a solid foundation is essential to deliver a successful software product. Your PoC, prototypes, and MVP will be your foundation for the process, with actual feedback. They will help you to iterate the product process and enhance the features to meet the user requirements or the ‘real-needs’.
However, software product development is not limited to paying attention only to the initial process but is involved with many crucial steps that need to be considered throughout the proceeding. With that note, the next phase of the development process will be discussed in future articles.
PoCs, MVPs, Prototypes & Throw Away Codebases for Software Product Development
The development of a successful software product requires excellent preparation with a series of steps. Brainstorming, planning, incorporating ideas, designing, QA are a few actions that are involved with the proceeding of product development. Each step helps to validate the stability and the effectiveness of the final product, and hence it is crucial to give equal attention every step of the way.
This is the second of our series of articles where we look into the basic elements that every expertise considers before developing a comprehensive software product. If you would like to keep up from inception, check our first article using the link below.
Link to our first article – The Essential Guide to Software Product Development.
If you are involved in a startup that is based on a new software product, these articles can help you understand the basics of how to go about it in the most economical and methodical way.
Disclaimer
This is based on 20+ years of experience in software product development. After seeing projects succeed, fail, survive, happy clients, angry clients etc. Encountering a mix of positive and negative things has helped this article to chip in a balanced view. It will further assist to learn how to succeed or fail with minimum damages or minimize disasters.
Significance of Software Development for Businesses
Software products have become one of the crucial needs to enhance and upscale any business. Automation of processes through software development helps to cut downtime and manual techniques for a smooth operation.
Streamline of internal functions, improved client experiences, feature-rich additions to the market are some top-notch features of software products that have made it super consumer effective while growing its popularity in every industry.
Problem Analysis
When you boil it all down, you will notice that the initial step of software development is identifying the problem. In other words, the need for a software product comes with addressing a particular issue.
Identifying and addressing the problem will ensure that you have developed the right solution as a software product. However, it is also essential to reckon that the problem and the requirements can be transitory and are likely to change over time.
Looking into the end-users or the target market is another critical point here. While collecting brick by brick for the development process, it is essential to pick out where your final product is going to fall. This could be Business-to-Business (B2B), Business-to-consumer (B2C), Business-to-Business-to-Consumer (B2B2C), or an internal software product development.
Once you have identified the problem and where the final product falls, take notes and put it out in a writing document to present for a group of people or your team. This allows you to receive multiple perspectives and dig deeper to understand the root causes that affect and manifest the main problem.
Pinpointing the primary problem, connecting the contributing factors, identifying the affected people (Eg, project sponsor, customer, user, management), defying the scope of the solution, and recognizing the solution constraints helps to analyze the problem, understand the affected areas and address them accordingly.
Idea Validation
The ultimate goal of idea validation is gathering evidence that your project will end with a paying customer or increase efficiency (to save time or cost). It helps to see the viability of your concept and how it will work in the real world.
Idea validation helps to reduce risks, speed up delivery and minimize costs. Below are a few questions to analyze the demand for your idea or to determine what the final product will achieve.
- Are you targeting the right audience with the correct problems?
- Can the final product help customers/users get their jobs done?
- How often do they need to use the product?
- Can your app solve a problem in a new way? Or is their innovation involved?
Setting up measurable and clear objectives is essential to determine how the idea will validate in the real world. In addition, formulating a hypothesis, developing a value proposition further enables you to get a clear answer.
PoC, Prototype, and MVP
A substantial part of idea validation is covered by following three main ways; use of a Proof of Concept (POC), Prototypes, or a Minimum Viable Product (MVP).
To make it more comprehensible, check out these working definitions for PoC, Prototype, and MVP.
PoC- Works in a controlled environment with a set of preconditions. Typically, a PoC is operated by the technical team and cannot be used by the outside world. However, PoC helps to demonstrate the core challenges or the processes for a particular problem can be addressed using the solution proposed.
Prototype- Gives a clear picture of the design and the user journeys of the application to make sure end-users could use the application conveniently. Users can mainly see the UI/UX aspects here but not the internal functionality.
MVP – A segment of the target audience will use MVP to solve a real-world problem. An MVP is bound with limitations and may not have many features. But the core functionality can be used to benefit from the system.
Depending on the situation, software companies use PoC, Prototypes, MVP or a combination to validate and receive feedback for the final solution.

Proof Of Concept (POC)
A PoC helps to pursue ideas before approving them for further testing. It helps to identify the feasibility of the concept and identify potential issues that may affect the final product’s success. Using a PoC, you can determine whether the product can feasibly develop to solve the problem you are trying to solve.
For the most part, a PoC is developed internally in a controlled environment and cannot be assembled or changed. It is a skeleton of the final product with minimal features to test out and distinguish how it will work in the real world.
Given below are a few advantages of developing a PoC during software development.
- It helps to choose the most appropriate technology for the development process.
- Simplify and improve the software functionality
- Receiving valuable feedback before building the actual product
- Potential to get onboard clients before official product release
- Avoid costly mistakes
- Increases the chances of commercial success

Prototyping
A Prototype is an iterative process that is used to ascertain the UI/UX aspect and visualize your product to validate the user journeys. It will demonstrate the critical design elements and the user flows using wireframes and storyboards. It helps define the features that need to be included and makes up a model to expose the errors in studying and designing.
Typically, there are four prototyping models, namely, Rapid, Evolutionary, Incremental, and Extreme. In most cases, following a PoC, a prototype is used to obtain further details of your final product and to see how it looks and users would use the features in the end.
Identifying customer needs, enhancing product workflow with better understanding, identifying design and related mistakes are a few advantages of prototyping in your early product development process.
Most importantly, you can also use it as an opportunity to reach the users at an early stage and get their feedback before putting your product into the market.

Credential App


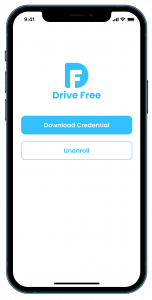
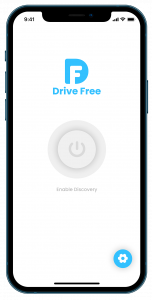

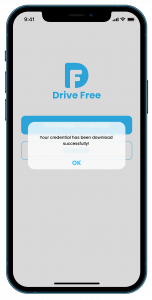
Reader App


Link to walkthrough a sample prototype
Prototype of Credential App – Live demo
Prototype of Reader App – Live demo
Minimum Viable Product (MVP)
Typically, before releasing a full-fledged product, an MVP is used to collect feedback from early customers. The responses from the real world help developers to work on the versions and improve the product accordingly.
An MVP consists of the core features and the minimalist design that deploys the final product. The basic infrastructure is developed using the least possible expenditures and has certain limitations. Positive and negative feedback received from MVP help validate the idea of the final product and see the potentiality of its success. It can also be used to solve an existing problem or could be used to improve the efficiency (cut down of effort taken, time taken, or cost involved) of a task.
MVP introduces efficiency to a selected task (core problem your application solve), and there could be many other auxiliary features that could improve the efficiency of the same job. But with the MVP mindset, you will not try to include those complementary features in the solution you provide at the MVP stage. So, again, that’s why we call it MVP. Solve the intended problem, but nothing more, nothing less.
There are different types of MVP concepts that can be used based on the purpose. Software prototypes, product designs, concierge, landing pages, piecemeal, demo videos, and wizard of Oz are some of the main ways the MVP concept is used. Dropbox, Amazon, Airbnb, and Facebook are a few well-known examples that started with the MVP technique.
Below are the key advantages of using MVP.
⦁ Avoid lengthy unnecessary work
⦁ Gain insights on product viability and usability
⦁ Saves project time and money
⦁ It gives clarity around the final product idea
⦁ Analyze market demand

When you disregard all non-essential features, that brings the time to market your product less and cost to develop your product less. These are the pillars of lean product development.
Choosing between POCs, Prototypes, and MVPS could be crucial to find the aptest solution for your business proposition. Furthermore, after considering all these essentials, you could decide on selecting them as throwaway codebase elements or not. Hence, our preceding context will discuss the guidelines and the necessities to choose between these elements.
We want to thank Chalinda Abeykoon for being a part of this effort and adding value to this article by sharing his insights and experience.
Stay tuned for our next article.